This article first appeared on the WeChat public account GTOC.
Quantization is widely used in industry to improve the training and inference efficiency of large models and reduce cost, which has led to many floating-point precisions and formats such as TF32, BF16, FP8, and FP4.
In AI chip virtual prototyping, FPU hardware models are generally simulated with software floating point. This is often implemented in C/C++, which keeps accuracy high while remaining reasonably fast.
Common simulators, such as QEMU TCG, use the Berkeley SoftFloat-3 open-source library (which follows IEEE 754) to emulate floating-point computation.

After extensive community refactoring, QEMU SoftFloat now provides a unified implementation path for 16/32/64-bit floating-point operations and supports configurable NaN propagation rules and rounding overflow modes, which makes guest FPU emulation easier.
However, 4-bit and 8-bit floating-point precisions are not yet supported.
GEM5 also integrates the Berkeley SoftFloat-3 open-source library to implement cross-platform floating-point operations and ensure that the results comply with IEEE 754.
This article first introduces the floating-point formats commonly used by LLMs.
Introduction to the floating-point standard
Floating-point values can be represented like this:

In other words, the actual value of a floating-point number equals the sign bit multiplied by the exponent bias, then multiplied by the fraction.
So, in a computer, a floating-point number can also be split into these three parts.
According to IEEE 754, the binary representation of a floating-point format consists of three parts: sign, exponent, and fraction, and is stored in sign-magnitude form (little-endian).

Sign-magnitude representation means that, when computers perform arithmetic, negative numbers need to be encoded in binary form.
As shown above, the sign bit occupies the most significant bit, with 0 for positive numbers and 1 for negative numbers; the exponent occupies the next most significant e bits; the fraction occupies the least significant f bits.
The specific values of e and f vary with the floating-point precision and format.
It is worth noting how the exponent is calculated.
For convenience, IEEE defines the exponent of a floating-point number by adding a fixed offset to its actual exponent.
The fixed offset is 2^(e-1) - 1, where e is the bit width of the stored exponent.
The resulting value is called the exponent bias and represents the encoded value of the exponent field.
This definition has the advantage that all exponent values can be represented with an unsigned integer of e bits.
This also makes it easier to compare the exponents of two floating-point numbers (in fact, the values of two floating-point representations can be compared lexicographically).
This biased representation of the exponent is also called the characteristic in Chinese technical usage.
If the encoded exponent value is in the range (0, 2^e - 2) and, in scientific notation, the most significant bit of the fraction is 1, then the floating-point number is called a normalized floating-point number. “Normalized” means using a unique floating-point form to represent a value.
Take the decimal number 5.0 in single-precision floating-point format as an example:

Its binary form is 101.0, which in scientific notation is 1.01 * 2^2. At this point:
The integer part is 1 (which satisfies the condition that the most significant bit is 1) and is implicit in the fraction; the actual exponent is 2, and the fractional part of the fraction field is 01 (that is, 0.01 in binary).
Because the fixed bias for single-precision floating point is 127 (2^7 - 1), the encoded exponent value is 2 + 127 = 129. This value is within the range (0, 254).
Now let us assemble the full binary representation of this floating-point number:

This value is the unique normalized form of 5.0.
Normalized floating-point numbers are suitable for most ordinary floating-point operations and provide a wide numerical range and high precision. For example, in single-precision (32-bit) floating-point numbers, only 23 bits are used to store the fraction, but this actually represents 24 bits of precision.
In addition to normalized floating-point numbers, there are subnormal floating-point numbers.
A subnormal floating-point number is defined as one whose encoded exponent is 0 and whose fraction is non-zero. In general, subnormal form is used only when a number is very close to zero.
The IEEE 754 standard specifies that the exponent bias of a subnormal floating-point number is 1 less than that of a normalized floating-point number.
For example, the smallest normalized single-precision floating-point number has an encoded exponent value of 1 and an actual exponent of -126; a subnormal single-precision floating-point number has an encoded exponent value of 0, but the corresponding actual exponent is also -126 rather than -127.
In practice, subnormal floating-point numbers are still valid and usable; they simply have an absolute value smaller than that of all normalized floating-point numbers. In other words, all subnormal floating-point numbers are closer to 0 than normalized floating-point numbers.
The following table summarizes the differences between normalized and subnormal floating-point numbers:
| Comparison | Normalized form | Subnormal form |
|---|---|---|
| Exponent encoding | Exponent field is in (0, 2^e - 2); e is the exponent bit width | Exponent field is 0, and the fraction is non-zero |
| Exponent bias | Uses the standard fixed bias (for example, 127 in single precision) | Uses a bias one less than the normalized form (for example, single precision keeps the same actual exponent as the smallest normalized value) |
| Fraction significand | Leading 1 is implicit; significand range [1,2) in binary scientific notation | Leading 0 is implicit; significand range (0,1) |
| Typical use | Main form for nonzero, non-special values | Used near zero to fill the gap between zero and the smallest normalized number |
There are also several special floating-point values worth mentioning:
If the exponent is 0 and the fractional part of the significand is 0, the number is ±0 (depending on the sign bit).
If exponent = 2^e − 1 and the fractional part of the significand is 0, the number is ±∞ (also depending on the sign bit).
If exponent = 2^e − 1 and the fractional part of the significand is non-zero, the number is represented as NaN.
Let us also discuss floating-point comparison and rounding.
Floating-point numbers can basically be compared lexicographically by sign bit, exponent field, and significand field in that order. Obviously, all positive numbers are greater than all negative numbers; when the signs are the same, the larger binary exponent corresponds to the larger absolute value.
The IEEE standard defines four different floating-point rounding modes:
Round to nearest, ties to even (the default rounding mode): rounds to the nearest representable value, and when two values are equally close, it chooses the even one (the one ending in 0 in binary).
Round toward +∞: rounds the result toward positive infinity.
Round toward -∞: rounds the result toward negative infinity.
Round toward 0: rounds the result toward zero.
Common floating-point formats
In addition to the double-, single-, and half-precision formats defined by IEEE 754, LLM quantization has also extended to 8-bit and 4-bit precisions (INT3/INT5/INT6 are used less often), and the floating-point formats are similar.
Let us first discuss the traditional double-, single-, and half-precision floating-point formats.
Double-precision floating-point is a data type used to represent floating-point numbers. It occupies 64 bits (8 bytes) in memory, so it is also called float64 or FP64.
In IEEE 754, this 64-bit binary format is formally called binary64, and in IEEE 754-1985 it was called double, i.e. double precision.
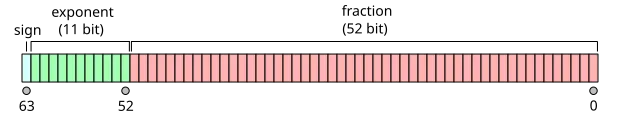
Single-precision floating-point is a data type used to represent floating-point numbers. It occupies 32 bits (4 bytes) in memory, so it is also called float32 or FP32.
In IEEE 754, this 32-bit binary format is formally called binary32, and in IEEE 754-1985 it was called single, i.e. single precision.

Half-precision floating-point is a data type used to represent floating-point numbers. It occupies 16 bits (2 bytes) in memory, so it is also called float16 or FP16.
In IEEE 754, this 16-bit binary format is formally called binary16. Because it is half the size of single-precision floating point, it is also simply called half, i.e. half precision. This data type is suitable only for numbers that do not require high precision; it is not suitable for computation.
Next we discuss the special floating-point precisions extended in LLM quantization.
Special floating-point formats
The following table summarizes common floating-point precisions.
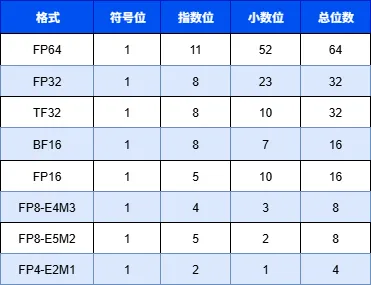
The corresponding bit-field diagrams are as follows:
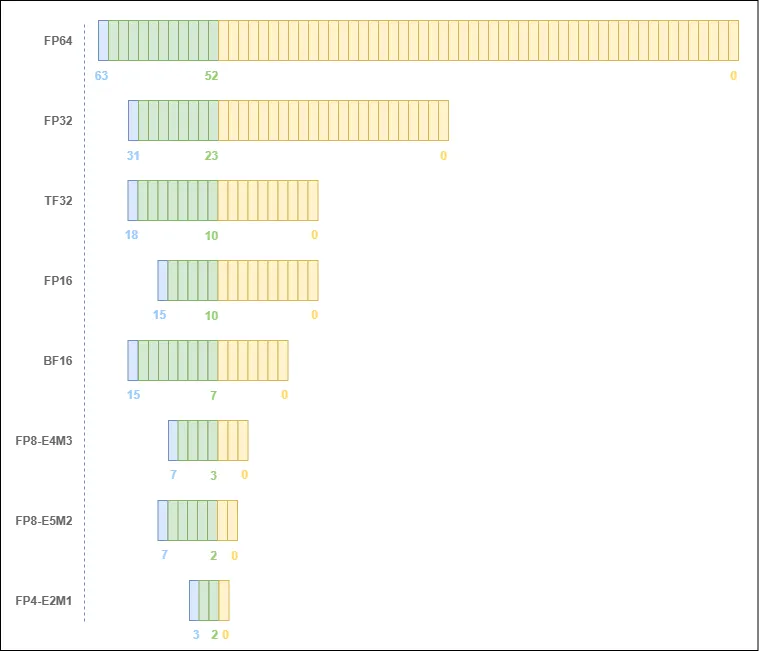
Let us go through them one by one.
TF32 (Tensor Float 32) is a special numeric type designed by NVIDIA for machine learning. It was intended to replace FP32 and was first supported on the A100 GPU.
Its structure consists of 1 sign bit, 8 exponent bits (aligned with FP32 exponent bits), and 10 fraction bits (aligned with FP16 fraction bits), for an actual width of 19 bits.
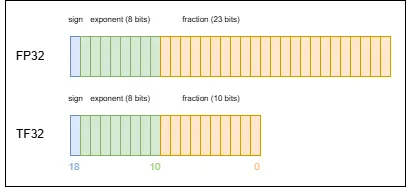
This design strikes a balance between performance, numeric range, and precision: it retains a range close to FP32 (thanks to the 8 exponent bits) while reducing computation and storage cost by shrinking the fraction field, and its precision is sufficient for most machine-learning workloads, making it well suited to improve efficiency in training and inference.
BF16 (Brain Float 16) is a floating-point format designed by Google Brain specifically for machine learning. Its structure consists of 1 sign bit, 8 exponent bits, and 7 fraction bits.
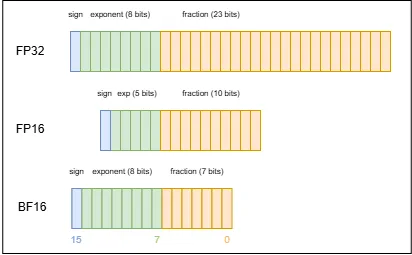
Relation to FP32: the exponent field is the same as FP32 (8 bits), so its range matches FP32 and conversion between the two is convenient; however, it has only 7 fraction bits (FP32 has 23), so its precision is much lower than FP32.
Relation to FP16: it has fewer fraction bits than FP16 (FP16 has 10), so its precision is lower than FP16; but it has more exponent bits than FP16 (FP16 has 5), so its range is larger than FP16.
On the hardware side, BF16 is supported only on NVIDIA’s Ampere architecture and later GPUs, making it suitable for machine-learning workloads that balance storage/computation cost and model quality.
FP8-E4M3 and FP8-E5M2 are two 8-bit floating-point data types designed to accelerate deep-learning inference, jointly developed by NVIDIA, ARM, and Intel.
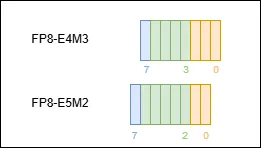
FP8-E4M3: contains 1 sign bit, 4 exponent bits, and 3 mantissa bits. The maximum storable value is approximately ±448, along with NaN, and it offers relatively high precision.
FP8-E4M3 is typically suitable for the forward pass of neural networks. In the forward pass, activations and weights need higher precision to ensure accurate results, and FP8-E4M3 can satisfy this requirement well.
FP8-E5M2: contains 1 sign bit, 5 exponent bits, and 2 mantissa bits. The maximum storable value is approximately ±57344, and it also supports ±inf and NaN. With more exponent bits, it has a larger dynamic range, but because it has fewer mantissa bits, its precision is relatively lower.
FP8-E5M2 is more suitable for the backward pass of neural networks. In backpropagation, gradients are less sensitive to precision, but they require a larger dynamic range, and the characteristics of FP8-E5M2 make it a better fit.
Compared with FP32 and FP16, FP8 data types use less storage, which improves model throughput and reduces latency. For compute-intensive operations such as matrix multiplication and convolution, FP8 can process more data with the same hardware resources, thereby improving computational efficiency.
Finally, let us talk about FP4.
FP4 has two variants, NVFP4 and MXFP4. Both are 4-bit floating-point (FP4) formats. Their core commonality is that both use the E2M1 data type, consisting of 1 sign bit, 2 exponent bits, and 1 mantissa bit, for a total width of 4 bits. They are suitable for low-precision computation scenarios to save memory and improve efficiency.
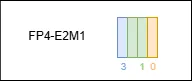
The main differences between the two are in two areas:
Quantization block size: NVFP4 uses a block size of 1×16, meaning quantization is performed in blocks of 1 row by 16 columns; MXFP4 uses a block size of 1×32, meaning the quantization unit is a block of 1 row by 32 columns. A larger block may affect quantization granularity and the preservation of precision.
Expansion-factor type: NVFP4 uses the E4M3 data type as its expansion factor, while MXFP4 uses E8M0. The difference in expansion factor may affect the ability to extend numeric range and the way precision is compensated, thereby influencing the overall dynamic range and accuracy of computation (NVFP4 is more precise than MXFP4).
FP4-E2M1 can significantly reduce VRAM usage because each floating-point number occupies only 4 bits, which greatly lowers storage requirements compared with FP16 (16 bits) or FP32 (32 bits).
At the same time, when combined with specific hardware acceleration units, such as Tensor Cores in NVIDIA’s Blackwell architecture, it can achieve higher compute throughput.
However, due to limits in dynamic range and precision, using FP4-E2M1 directly may cause accuracy loss during model training and inference. In particular, for tasks that require high precision, such as some complex language-model workloads, FP4-E2M1 may not retain enough precision.
Summary
We have now covered the common floating-point precisions and formats. Due to space constraints, the next article will explain how to extend QEMU’s SoftFloat library to support more floating-point precisions.
Image and source references:
[1] Wikipedia - IEEE 754 [2] Zhihu - A detailed explanation and practice guide to precision issues in large LLMs (FP16, FP32, BF16) [3] Zhihu - How many precisions are involved in large models? A clear explanation of the relationships among FP32, TF32, FP16, BF16, FP8, FP4, NF4, and INT8 [4] Scaleway Docs - Understanding the NVIDIA FP8 format [5] Paper - FP8 Formats for Deep Learning [6] Paper - LLM-FP4: 4-Bit Floating-Point Quantized Transformers