QEMU’s softfloat source code lives under the fpu/ and include/fpu/ paths. The code originally came from version 2a of the Berkeley SoftFloat IEC/IEEE floating-point package (SoftFloat-2a) and was later modified by QEMU contributors.
I have now added support for tfloat32, float8e4m3, and float8e5m2 to softfloat; the code can be obtained from the repository below:
1git clone -b neural-network-softfloat https://gitee.com/gevico/qemu.git
The source tree is as follows:
1include/fpu
2|-- softfloat-helpers.h # standalone helpers, used for initialization such as setting the rounding mode and exception mode
3|-- softfloat-macros.h # QEMU floating-point support macros
4|-- softfloat-types.h # defines floating-point precisions and formats
5`-- softfloat.h # floating-point interfaces for external use, such as floating-point operations and precision conversion
6
7fpu/
8|-- meson.build # build script
9|-- softfloat-parts-addsub.c.inc
10|-- softfloat-parts.c.inc
11|-- softfloat-specialize.c.inc # special implementations for some floating-point operations
12`-- softfloat.c # core source code for floating-point functionality
To add a new floating-point precision to softfloat, complete the following steps:
- Add the new floating-point precision definition in softfloat-types.h
- Implement the key floating-point arithmetic functions in softfloat.c
- Implement the special floating-point functions in softfloat-specialize.c.inc
- Add the precision interface declarations in softfloat.h
Below, we use tfloat32 (Tensor float32, TF32) as the example.
Add the new floating-point precision definition in softfloat-types.h
tfloat32 has the following floating-point format:
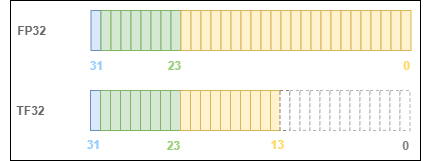
Internally, tfloat32 still performs computation as float32; it only keeps the first 10 bits of the float32 fraction in its output value.
Let’s add the tfloat32 definition.
1// path: include/fpu/softfloat-types.h
2
3/*
4 * Software neural-network floating-point types.
5 */
6typedef uint16_t bfloat16;
7typedef uint32_t tfloat32; /* Define TF32 */
8
9/* Some helper macros, following the other precision definitions. */
10#define tfloat32_val(x) (x)
11#define make_tfloat32(x) (x)
Implement the key floating-point arithmetic functions in softfloat.c
To improve portability and code reuse, softfloat uses a pack/unpack model to handle floating-point formats. The actual arithmetic is performed by unpacking the floating-point value and then computing the sign, exponent, and fraction separately.
So we first need to add the float format definition for tfloat32, as shown below:
1// path: fpu/softfloat.c
2
3/* Expand fields based on the size of exponent and fraction */
4#define FLOAT_PARAMS_(E) \
5 .exp_size = E, \
6 .exp_bias = ((1 << E) - 1) >> 1, \
7 .exp_re_bias = (1 << (E - 1)) + (1 << (E - 2)), \
8 .exp_max = (1 << E) - 1
9
10#define FLOAT_PARAMS(E, F) \
11 FLOAT_PARAMS_(E), \
12 .frac_size = F, \
13 .frac_shift = (-F - 1) & 63, \
14 .round_mask = (1ull << ((-F - 1) & 63)) - 1
15
16/* Define the floatfmt for tfloat32. */
17static const FloatFmt tfloat32_params = {
18 FLOAT_PARAMS(8, 23)
19};
20
21/* Unpack a float to parts, but do not canonicalize. */
22static void unpack_raw64(FloatParts64 *r, const FloatFmt *fmt, uint64_t raw)
23{
24 const int f_size = fmt->frac_size;
25 const int e_size = fmt->exp_size;
26
27 *r = (FloatParts64) {
28 .cls = float_class_unclassified,
29 .sign = extract64(raw, f_size + e_size, 1),
30 .exp = extract64(raw, f_size, e_size),
31 .frac = extract64(raw, 0, f_size)
32 };
33}
34
35/* Pack a float from parts, but do not canonicalize. */
36static uint64_t pack_raw64(const FloatParts64 *p, const FloatFmt *fmt)
37{
38 const int f_size = fmt->frac_size;
39 const int e_size = fmt->exp_size;
40 uint64_t ret;
41
42 ret = (uint64_t)p->sign << (f_size + e_size);
43 ret = deposit64(ret, f_size, e_size, p->exp);
44 ret = deposit64(ret, 0, f_size, p->frac);
45 return ret;
46}
47
48/* Define the unpack function */
49static void QEMU_FLATTEN tfloat32_unpack_raw(FloatParts64 *p, tfloat32 f)
50{
51 unpack_raw64(p, &tfloat32_params, f);
52}
53
54static void tfloat32_unpack_canonical(FloatParts64 *p, tfloat32 f,
55 float_status *s)
56{
57 tfloat32_unpack_raw(p, f);
58 parts_canonicalize(p, s, &tfloat32_params);
59}
60
61/* Define the pack function; when packing, keep only the first 10 fraction bits. */
62static tfloat32 QEMU_FLATTEN tfloat32_pack_raw(const FloatParts64 *p)
63{
64 /* The fraction is kept to only its first 10 bits. */
65 return pack_raw64(p, &tfloat32_params) & 0xFFFC0000;
66}
67
68/* Wrap the rounding mode used by packing */
69static tfloat32 tfloat32_round_pack_canonical(FloatParts64 *p,
70 float_status *s)
71{
72 parts_uncanon(p, s, &tfloat32_params);
73 return tfloat32_pack_raw(p);
74}
Then we add the concrete arithmetic functions. There are many of them, so we will use add/sub and precision conversion as examples:
1static tfloat32 QEMU_FLATTEN
2tfloat32_addsub(tfloat32 a, tfloat32 b, float_status *status, bool subtract)
3{
4 FloatParts64 pa, pb, *pr;
5
6 tfloat32_unpack_canonical(&pa, a, status);
7 tfloat32_unpack_canonical(&pb, b, status);
8 pr = parts_addsub(&pa, &pb, status, subtract);
9
10 return tfloat32_round_pack_canonical(pr, status);
11}
12
13tfloat32 tfloat32_add(tfloat32 a, tfloat32 b, float_status *status)
14{
15 return tfloat32_addsub(a, b, status, false);
16}
17
18tfloat32 tfloat32_sub(tfloat32 a, tfloat32 b, float_status *status)
19{
20 return tfloat32_addsub(a, b, status, true);
21}
22
23/* Use conversion between tfloat32 and float32 as an example. */
24
25float32 tfloat32_to_float32(tfloat32 a, float_status *s)
26{
27 FloatParts64 p;
28
29 tfloat32_unpack_canonical(&p, a, s);
30 parts_float_to_float(&p, s);
31 return float32_round_pack_canonical(&p, s);
32}
33
34tfloat32 float32_to_tfloat32(float32 a, float_status *s)
35{
36 FloatParts64 p;
37
38 float32_unpack_canonical(&p, a, s);
39 parts_float_to_float(&p, s);
40 return tfloat32_round_pack_canonical(&p, s);
41}
Implement the special floating-point functions in softfloat-specialize.c.inc
Only two functions need to be implemented: tfloat32_is_quiet_nan() and tfloat32_is_signaling_nan().
1/*----------------------------------------------------------------------------
2| Returns 1 if the tfloat32 value `a' is a quiet
3| NaN; otherwise returns 0.
4*----------------------------------------------------------------------------*/
5
6bool tfloat32_is_quiet_nan(tfloat32 a_, float_status *status)
7{
8 if (no_signaling_nans(status)) {
9 return tfloat32_is_any_nan(a_);
10 } else {
11 uint32_t a = tfloat32_val(a_);
12 if (snan_bit_is_one(status)) {
13 return (((a >> 22) & 0x1FF) == 0x1FE) && (a & 0x003FFFFF);
14 } else {
15 return ((uint32_t)(a << 1) >= 0xFF800000);
16 }
17 }
18}
19
20/*----------------------------------------------------------------------------
21| Returns 1 if the tfloat32 value `a' is a signaling
22| NaN; otherwise returns 0.
23*----------------------------------------------------------------------------*/
24
25bool tfloat32_is_signaling_nan(tfloat32 a_, float_status *status)
26{
27 if (no_signaling_nans(status)) {
28 return 0;
29 } else {
30 uint32_t a = tfloat32_val(a_);
31 if (snan_bit_is_one(status)) {
32 return ((uint32_t)(a << 1) >= 0xFF800000);
33 } else {
34 return (((a >> 22) & 0x1FF) == 0x1FE) && (a & 0x003FFFFF);
35 }
36 }
37}
Add precision interface declarations in softfloat.h
In addition to declaring the tfloat32-related functions defined in softfloat.c and softfloat-specialize.c.inc, we also need to add some common inline functions in the softfloat.h header.
The implementation is shown below, with key excerpts:
1static inline tfloat32 tfloat32_abs(tfloat32 a)
2{
3 /* Note that abs does *not* handle NaN specially, nor does
4 * it flush denormal inputs to zero.
5 */
6 return make_tfloat32(tfloat32_val(a) & 0x7fffffff);
7}
8
9static inline tfloat32 tfloat32_chs(tfloat32 a)
10{
11 /* Note that chs does *not* handle NaN specially, nor does
12 * it flush denormal inputs to zero.
13 */
14 return make_tfloat32(tfloat32_val(a) ^ 0x80000000);
15}
16
17static inline bool tfloat32_is_infinity(tfloat32 a)
18{
19 return (tfloat32_val(a) & 0x7fffffff) == 0x7f800000;
20}
21
22static inline bool tfloat32_is_neg(tfloat32 a)
23{
24 return tfloat32_val(a) >> 31;
25}
26
27static inline bool tfloat32_is_zero(tfloat32 a)
28{
29 return (tfloat32_val(a) & 0x7fffffff) == 0;
30}
31
32static inline bool tfloat32_is_any_nan(tfloat32 a)
33{
34 return ((tfloat32_val(a) & ~(1 << 31)) > 0x7f800000UL);
35}
36
37static inline bool tfloat32_is_zero_or_denormal(tfloat32 a)
38{
39 return (tfloat32_val(a) & 0x7f800000) == 0;
40}
41
42static inline bool tfloat32_is_normal(tfloat32 a)
43{
44 return (((tfloat32_val(a) >> 23) + 1) & 0xff) >= 2;
45}
46
47static inline bool tfloat32_is_denormal(tfloat32 a)
48{
49 return tfloat32_is_zero_or_denormal(a) && !tfloat32_is_zero(a);
50}
1static inline bool tfloat32_is_zero_or_normal(tfloat32 a)
2{
3 return tfloat32_is_normal(a) || tfloat32_is_zero(a);
4}
5
6static inline tfloat32 tfloat32_set_sign(tfloat32 a, int sign)
7{
8 return make_tfloat32((tfloat32_val(a) & 0x7fffffff) | (sign << 31));
9}
10
11static inline bool tfloat32_eq(tfloat32 a, tfloat32 b, float_status *s)
12{
13 return tfloat32_compare(a, b, s) == float_relation_equal;
14}
15
16static inline bool tfloat32_le(tfloat32 a, tfloat32 b, float_status *s)
17{
18 return tfloat32_compare(a, b, s) <= float_relation_equal;
19}
20
21static inline bool tfloat32_lt(tfloat32 a, tfloat32 b, float_status *s)
22{
23 return tfloat32_compare(a, b, s) < float_relation_equal;
24}
25
26static inline bool tfloat32_unordered(tfloat32 a, tfloat32 b, float_status *s)
27{
28 return tfloat32_compare(a, b, s) == float_relation_unordered;
29}
30
31static inline bool tfloat32_eq_quiet(tfloat32 a, tfloat32 b, float_status *s)
32{
33 return tfloat32_compare_quiet(a, b, s) == float_relation_equal;
34}
35
36static inline bool tfloat32_le_quiet(tfloat32 a, tfloat32 b, float_status *s)
37{
38 return tfloat32_compare_quiet(a, b, s) <= float_relation_equal;
39}
40
41static inline bool tfloat32_lt_quiet(tfloat32 a, tfloat32 b, float_status *s)
42{
43 return tfloat32_compare_quiet(a, b, s) < float_relation_equal;
44}
45
46static inline bool tfloat32_unordered_quiet(tfloat32 a, tfloat32 b,
47 float_status *s)
48{
49 return tfloat32_compare_quiet(a, b, s) == float_relation_unordered;
50}
51
52#define tfloat32_zero 0
53#define tfloat32_half 0x3f000000
54#define tfloat32_one 0x3f800000
55#define tfloat32_one_point_five 0x3fc00000
56#define tfloat32_two 0x40000000
57#define tfloat32_three 0x40400000
58#define tfloat32_infinity 0x7f800000
In the next article, we will explain how to validate the correctness of the newly added floating-point precisions using QEMU’s FPU test framework.